
はじめまして、株式会社ハイサイの開発エンジニアT.Iです。
基本スペック
開発: Rails (Backend) 6年 / React (Frontend) 3年
インフラ: AWS (EC2, RDS, S3, EKS, etc.)
その他: PM経験、テックリード経験
趣味: 音ゲー、徒歩旅、DTM

また、最近は土日にClaude Codeにコードを書かせたりもしています。大学生の頃にも個人開発のようなことをしていましたが、あの頃と違って面倒な実装に1日を費やすこともなくなりました。いい時代になりましたね。
今回は、ClaudeやGeminiをはじめとした、AIエージェントについてお話しします。
はじめに
昨今のAIエージェントの進化は目覚ましく、コーディングに限らず、資料の要約や質問への回答など、様々なことがAIエージェントで代替可能になりました。この前も、衣類乾燥機の取扱説明書を読むのが面倒で、取扱説明書のPDFを投げてGeminiに質問したりしました(笑)

ただ、こういった日常的な用途とは違い、業務ではGeminiに資料をポイっと投げるわけにもいきません。まず資料のほとんどが設計書や顧客情報など、社外秘の内容を含むもので、このまま投げてしまうと機密情報漏洩などセキュリティ面のリスクがあります。
また、業務では判断ミスが許されない局面があり、そこにAIを活用するとなると、ハルシネーションは最大の敵になります。しかし、ハルシネーションの起きにくい高精度モデルが使用できるプランは現状でも決して安くなく、今後もメモリ価格とともに高騰が予想されるため、コスト面のリスクも無視できません。
このセキュリティ面、コスト面の2つのリスクを解消できるのが「ローカルLLM」です。手元のPC上で動作する無料のAIで、すべての処理が内部で完結するため漏洩の心配もありません。
今回は、このローカルLLMを使ったRAG(*1)を構築して、PDFの内容に関する質問に回答してくれる「AI秘書」を作ってみました。PythonとOllamaだけあればノートPCでも動く手軽なものになっているので、ぜひ真似してやってみてください!

(*1) RAG: 生成AIが自らの学習データだけでなく社内文書などの情報を検索し、それをもとに回答を生成する技術。
実装の流れ
まず、ローカルLLMがPDFをそのまま読み取れるかと言うと、可能ですが、あまり現実的ではありません。(Visonモデルであれば可能ですが、PDFの読み取りにかなりの時間がかかります)
そこで、前段階でOCRという処理によって、PDF中のテキストを抽出する必要があります。
加えて、そのテキストをEmbeddingという処理によってベクトル化し、LLMが扱いやすい形にします。
最終的にベクトルストアと呼ばれるDBに保存して、LLMが質問(プロンプト)を受けた際に参照できるような、RAGの基本形を作っていきます。
スクリプトの実行フローとしては、下記のようになります!
(実行速度を上げるために、2段階でキャッシュを持たせています)

技術スタックとしては、それぞれ以下のものを使います。
- 言語: Python(3.14.5)+LangChain
- LLM実行基盤: Ollama
- ベクトルストア: Chroma
- LLM
- OCR用: qwen2.5vl:7b
- Embedding用: bge-m3
- プロンプト回答用: qwen3.5:4b
OllamaとPythonはインストールする必要があります。
Ollamaは下記のコマンドでインストールできます。
brew install ollama
# 使用するモデルのダウンロード
ollama pull qwen2.5vl:7b
ollama pull bge-m3
ollama pull qwen3.5:4b(Pythonはそれぞれお好きな入れ方で入れていただければと!)
実装コード
それでは早速実装していきましょう!まずは「OCRでPDFからテキストを抽出」の部分です。
コードを表示(ocr.py)
import os
import io
import base64
from pathlib import Path
import fitz # PyMuPDF
import requests
from PIL import Image
OLLAMA_BASE_URL = os.getenv("OLLAMA_HOST", "http://localhost:11434")
VISION_MODEL = "qwen2.5vl:7b"
OCR_PROMPT = (
"ページに含まれる全ての文字を、表や箇条書きの構造を可能な限り保持して書き起こしてください。\n"
"- 表は Markdown 表形式で出力してください\n"
"- 装飾・説明・注釈の追加は不要です\n"
"- 画像に存在しない情報は出力しないでください\n"
"- テキストのみを出力してください"
)
def _ollama_vision_extract(image: Image.Image) -> str:
buf = io.BytesIO()
image.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode()
res = requests.post(
f"{OLLAMA_BASE_URL}/api/generate",
json={
"model": VISION_MODEL,
"prompt": OCR_PROMPT,
"images": [b64],
"stream": False,
# コンテキストを広げて生成途中の KV キャッシュ・シフトを回避する。
# 256k は別の 500 エラーを誘発する報告があるため、ほどほどの値に留める。
"options": {"num_ctx": 16384},
},
timeout=600,
)
res.raise_for_status()
return res.json()["response"]
def ocr_pdf_pages(pdf: Path, dpi: int = 200) -> list[str]:
pages: list[str] = []
with fitz.open(pdf) as doc:
total = doc.page_count
for i, page in enumerate(doc, start=1):
pix = page.get_pixmap(dpi=dpi)
img = Image.open(io.BytesIO(pix.tobytes("png")))
print(f" OCR page {i}/{total} ...")
pages.append(_ollama_vision_extract(img))
return pagesocr_pdf_pagesでPDFの各ページを画像に変換し、1枚ずつ_ollama_vision_extractでOCR処理を実行しています。
このようなPDFが、

このような形式のjsonで抽出されます。この例では1ページのみなので、配列中の文字列が1つになっていますね。
(読みやすいように文字列のインデントは手で整えてあります)
コードを表示(json)
[
"
1. 概要 / Overview\n
\n
本ドキュメントはOCR(光学文字認識)の動作検証を目的として生成された\n
サンプルPDFです。日本語と英語が混在しており、見出し・本文・箇条書き・\n
表・数値などの代表的なレイアウト要素を含んでいます。\n
\n
This document is a sample PDF generated to verify OCR behavior.\n
It contains mixed Japanese and English text, headings, body text,\n
bullet lists, a table, and numeric values.\n
\n
2. 検証ポイント / Verification Points\n
\n
- 日本語テキストの認識精度 (ひらがな、カタカナ、漢字)\n
- 英数字と記号の認識: ABC abc 0123456789 !@#$%^&*()\n
- 全角・半角の区別: A B C a b c 0 1 2 3 / ABCabc0123\n
- 句読点と記号: 、 。「」『』()~・…\n
- 改行・段落の構造保持
"
](このOCRの部分だけで実行に数分かかります!)
続いて、「テキストをEmbeddingしてベクトルストアに保存」と、キャッシュ制御の部分です。
コードを表示(vector_store.py)
import json
import hashlib
from pathlib import Path
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_ollama import OllamaEmbeddings
from ocr import VISION_MODEL, ocr_pdf_pages
EMBEDDING_MODEL = "bge-m3"
OCR_CACHE_DIR = Path("./ocr_cache")
CHROMA_BASE_DIR = Path("./chroma_db")
def _pdf_hash(pdf: Path) -> str:
return hashlib.md5(pdf.read_bytes()).hexdigest()
def _cache_status(label: str, location: Path, *, populated: bool) -> bool:
"""キャッシュの有無をログ出力し、ヒットしたかどうかを返す。"""
if populated:
print(f"{label} cache hit: {location}")
return True
print(f"{label} cache miss: {location}")
return False
def _get_chunked_documents(pdf: Path) -> list[Document]:
cache_file = OCR_CACHE_DIR / f"{pdf.stem}.{_pdf_hash(pdf)}.json"
# OCRキャッシュの有無を判定、あればロードしてテキストを返す
if _cache_status("OCR", cache_file, populated=cache_file.exists()):
pages = json.loads(cache_file.read_text(encoding="utf-8"))
# OCRキャッシュがない場合はOCR処理して保存
else:
print(f" Running Vision OCR ({VISION_MODEL}) on {pdf} ...")
pages = ocr_pdf_pages(pdf)
cache_file.parent.mkdir(parents=True, exist_ok=True)
cache_file.write_text(json.dumps(pages, ensure_ascii=False), encoding="utf-8")
print(f" OCR cache saved: {cache_file}")
docs = [
Document(page_content=t, metadata={"source": str(pdf), "page": i + 1})
for i, t in enumerate(pages)
]
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
return splitter.split_documents(docs)
def find_or_create_vector_store(pdf_path: str | Path) -> Chroma:
pdf = Path(pdf_path)
embedding = OllamaEmbeddings(model=EMBEDDING_MODEL)
# PDF の中身が変わったら自動で別ディレクトリに作り直されるよう、ハッシュをパスに含める
persist_dir = CHROMA_BASE_DIR / f"{pdf.stem}_{_pdf_hash(pdf)[:12]}"
# Chromaキャッシュの有無を判定、あればロードして返す
populated = persist_dir.exists() and any(persist_dir.iterdir())
if _cache_status("Chroma", persist_dir, populated=populated):
return Chroma(persist_directory=str(persist_dir), embedding_function=embedding)
# Chromaキャッシュがない場合は新規作成して保存
print(f" Building vector store at {persist_dir} ...")
documents = _get_chunked_documents(pdf)
return Chroma.from_documents(
documents=documents,
embedding=embedding,
persist_directory=str(persist_dir),
)OCR後のテキストがocr_cache/配下、Chromaのデータがchroma_db/配下にキャッシュとして保存されます。2回目以降の実行の際、これらのファイルがあれば、OCR及びEmbeddingをスキップする形ですね。
最後に「プロンプト+ベクトルストア をLLMに投げる」の部分です。
コードを表示(main.py)
import argparse
from langchain_classic.chains import create_retrieval_chain
from langchain_classic.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import OllamaLLM
from vector_store import find_or_create_vector_store
LLM_MODEL = "qwen3.5:4b"
def get_rag_chain(retriever, llm, system_prompt):
question_answer_chain = create_stuff_documents_chain(
llm,
ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}"),
])
)
return create_retrieval_chain(retriever, question_answer_chain)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PDF に対する RAG 質問応答")
parser.add_argument("pdf_path", help="質問対象の PDF ファイルのパス")
parser.add_argument("input", help="LLM に投げる質問文")
args = parser.parse_args()
vector_store = find_or_create_vector_store(args.pdf_path)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
system_prompt = (
"以下の【参考コンテキスト】の情報に基づいて、"
"ユーザーの質問に正確に答えてください。\n\n"
"【参考コンテキスト】:\n{context}"
)
rag_chain = get_rag_chain(
retriever,
OllamaLLM(model=LLM_MODEL, reasoning=False),
system_prompt,
)
response = rag_chain.invoke({"input": args.input})
print("回答:", response["answer"])スクリプトの引数として、「PDFのパス」と「質問文」の2つを取っていて、実行のコマンドは下記になります。
python main.py {PDFのパス} {質問文}この「PDFのパス」から今までの処理を呼び出してベクトルストアを作成して、それと「質問文」をLLMに投げる処理を、LangChainで記述している形です。
あとは今までのスクリプトで必要になるライブラリをまとめたrequirements.txtを作成して、
ollama
ddgs
langchain
langchain-chroma
langchain-classic
langchain-ollama
tictoc
cryptography
pymupdf
Pillow
requests
reportlab下記コマンドでこれらのライブラリをインストールしたら、いよいよ実行です!
pip install -r requirements.txt実行
環境としてはM4 MackBook Air(24GB)でやってみました。
今回は検証用に4ページのsample.pdfを用意しました。
特に2ページ目の表と、4ページ目の画像中のテキストが読み取れるかがポイントになりそうです。

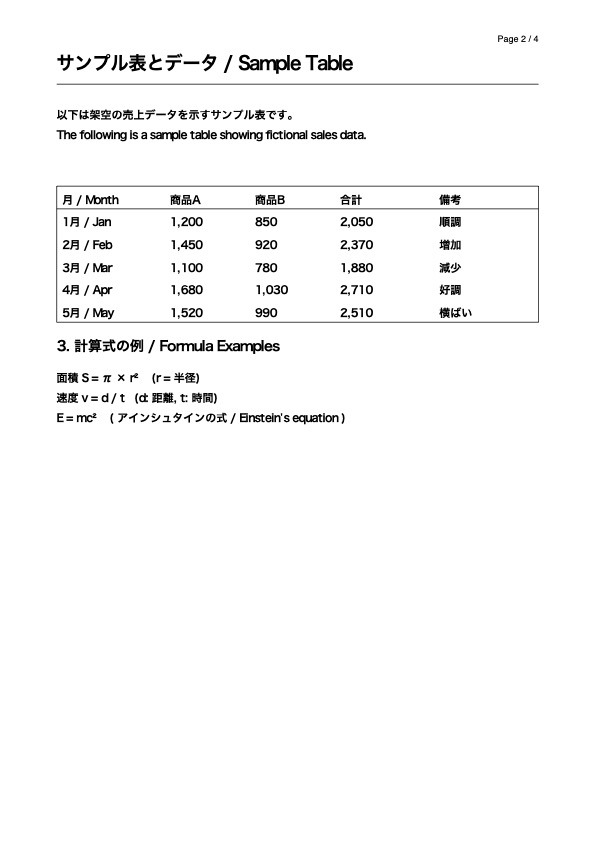


2ページ目の表について聞いてみましょう。
python main.py sample.pdf "商品A,Bのそれぞれの売上の平均を教えて"OCR処理が各ページ3分程度、合計12分程度で完了し、ベクトルストアへの保存は数秒程度で完了したようです。やはりここは長いですね…
その後、1分ほどかけてLLMが回答を出力してくれました!
% python main.py sample.pdf "商品A,Bのそれぞれの売上の平均を教えて"
Chroma cache miss. Building vector store at chroma_db/sample_c8bf14c443e7 ...
OCR cache miss. Running Vision OCR (qwen2.5vl:7b) on sample.pdf ...
OCR page 1/4 ...
OCR page 2/4 ...
OCR page 3/4 ...
OCR page 4/4 ...
OCR cache saved: ocr_cache/sample.c8bf14c443e7a11c1cacddf4437c7980.json
Chroma vector store created and cached at chroma_db/sample_c8bf14c443e7
回答: 提供された【参考コンテキスト】には、1 月から 5 月までの 5 か月の売上のデータが含まれており、商品 A と商品 B の各月の数値に基づいて平均を計算します。
計算過程は以下の通りです。
**1. 商品 A の売上**
* 1 月:1,200
* 2 月:1,450
* 3 月:1,100
* 4 月:1,680
* 5 月:1,520
合計:1,200 + 1,450 + 1,100 + 1,680 + 1,520 = **6,950**
月数:5
平均:6,950 ÷ 5 = **1,390**
**2. 商品 B の売上**
* 1 月:850
* 2 月:920
* 3 月:780
* 4 月:1,030
* 5 月:990
合計:850 + 920 + 780 + 1,030 + 990 = **4,570**
月数:5
平均:4,570 ÷ 5 = **914**
**結論**
* 商品 A の売上の平均は **1,390** です。
* 商品 B の売上の平均は **914** です。表の内容を正確に理解し、平均の計算もできていますね!
続いて4ページ目の画像について聞いてみます。
% python main.py sample.pdf "ブレンドコーヒーの単価を教えて"前回と同じPDFについて聞いているので、前回のChromaキャッシュを使ってくれました!また、今回は質問が簡単だったからか、20秒ほどで回答が返ってきました!
% python main.py sample.pdf "ブレンドコーヒーの単価を教えて"
Chroma cache hit: chroma_db/sample_c8bf14c443e7
回答: ブレンドコーヒーの単価は **480 円** です。
【参考コンテキスト】より以下の通りとなります:
| 品目 / Item | 単価 / Unit |
| --- | --- |
| ブレンドコーヒー Blend Coffee | 480 |画像中のテキストも読み取れています!
ちなみに、何回か同じことを聞いてみると、若干回答内容や回答フォーマットにブレがあることがわかります。この回はあっさりとした回答でした。
% python main.py sample.pdf "ブレンドコーヒーの単価を教えて"
Chroma cache hit: chroma_db/sample_c8bf14c443e7
回答: ブレンドコーヒーの単価は **480 円** です。これはTemperature(*2)によるもので、OllamaLLMのコンストラクタで0を渡すと回答のブレをなくすことができます。
OllamaLLM(model=LLM_MODEL, base_url=OLLAMA_BASE_URL, reasoning=False, temperature=0),今回の「AI秘書」のように、ドキュメントについて回答するような利用シーンであれば、Temperatureは低いほうがいいのかもしれませんね。
Temperature=0で他にもいろんな質問をしてみて、その回答をまとめてみました!
(回答時間はキャッシュありの場合のものです)
| 対象ページ | 質問 | 回答時間 | 回答の要約 |
| 1 | このドキュメントの概要を教えて | 19秒 | 「1.概要」の内容を箇条書きで要約 |
| 1 | このドキュメントには全角英字は登場しますか? | 25秒 | 「英数字と記号の認識」の「ABC」「abc」も全角英字だと言っているので、LLMが全角と半角を区別できていなさそう |
| 2 | 商品A,B,Cのそれぞれの売上の平均を教えて | 1分 | 商品A,Bのそれぞれの平均の算出結果と、商品Cのデータはないので回答できないという旨 |
| 2 | 面積の式を教えて | 10秒 | 面積の式の引用と、rが半径を表す旨 |
| 3 | 3ページ目のテキストの英語と日本語の内容は同じものについてですか? | 23秒 | 日本語(なぜか一部)と英語(全文)を引用し、全く異なる内容ですと回答それぞれの内容についての説明はなし |
| 3 | 3ページ目の英語のテキストの意味を教えて | 16秒 | なぜか1ページ目の英語テキストを和訳OCR後のテキストにページ情報がないので、文脈を見て確率的に高い方を回答した? |
| 4 | ブレンドコーヒーを3つ買うと税込いくらになりますか? | 18秒 | 480*3=1440、1440*0.10=144、1440+144=1584円参考コンテキストの「2 つで 1056円」に基づいて計算した旨も出力 |
| – | 日本の首都はどこですか? | 18秒 | 参考コンテキストには情報がないので回答できない旨と、一般的な知識として「東京」である旨 |
(*2)Temperature: LLMは次にくる確率の高い単語の上位何件かからランダムに選んで文章を生成するが、この「上位何件」の範囲を決める数値。0.0〜 1.0(モデルによって異なる)の範囲で、大きければ大きいほどランダム性が高い。
まとめ
今回は、Ollama+Python+LangChainでローカルLLMによる簡易的なRAGを構築して、「AI秘書」として動かしてみました。
PC1台のローカル環境でも、適切なモデル選定とキャッシュ戦略をとれば、ある程度動くRAGが作れることがわかりました!
ここから、複数のPDF資料を読み込ませるのは勿論、社内Wikiなどの外部サイトとローカル資料のどちらを参照するか自分で判断して動くなど、AIエージェントとして様々な拡張ができそうです。
ローカルLLMの性能の向上と共に、その活用ノウハウは今後重要になっていくかと思いますので、皆さんもこれを足がかりにAIエージェントを構築して、AI秘書を雇ってみてはいかがでしょうか?
当コラムの「AI秘書」作りが業務の効率化にお役立てできればうれしいです!
Author: T.I @High-SAI